



有时候我们会遇到这样的需求:不要让这个网站被收录。禁止收录?好像并没有那么简单,尤其是当网站内容优质时,搜索引擎很难“收”下留情。我最先想到的办法是通过<meta>标签禁止搜索引擎索引,或是robots.txt更精确的规定搜索引擎索引内容。
通过<meta>标签实现禁止搜索引擎索引:
1 | <meta name="robots" content="noindex"> //禁止所有搜索引擎索引 |
通过robots.txt实现禁止搜索引擎索引:
1 | User-agent: * |
事情并没有这么简单,经过观察和测试发现,百度好像并不遵从这种标准,依然会收录,所以还是不要把希望寄托在别人身上,想办法屏蔽百度蜘蛛便万事大吉了。最终,我通过nginx禁止搜索引擎的蜘蛛访问实现了这一需求,从根本上解决问题。
通过nginx禁止搜索引擎的UA访问:
1 | if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot") |
我基本上整理齐全了所有搜索引擎的UA,可以根据需求删减或增加。return 403当然可以返回404甚至444,也可以使用deny all或者其他更骚的方法。通过curl模拟百度user agent,nginx返回403。
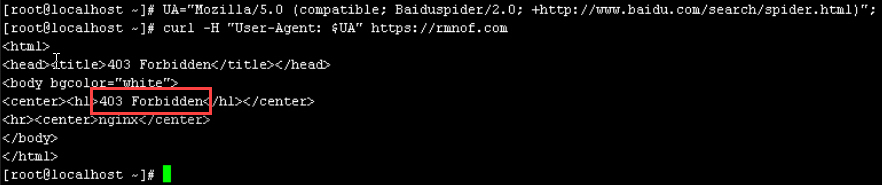
经过观察后得出结论:百度蜘蛛发现网站无法访问后,会停止收录并逐渐停止爬取。如果中间件是Apache,在htaccess入口文件中配置指令,同理但不同语法。



